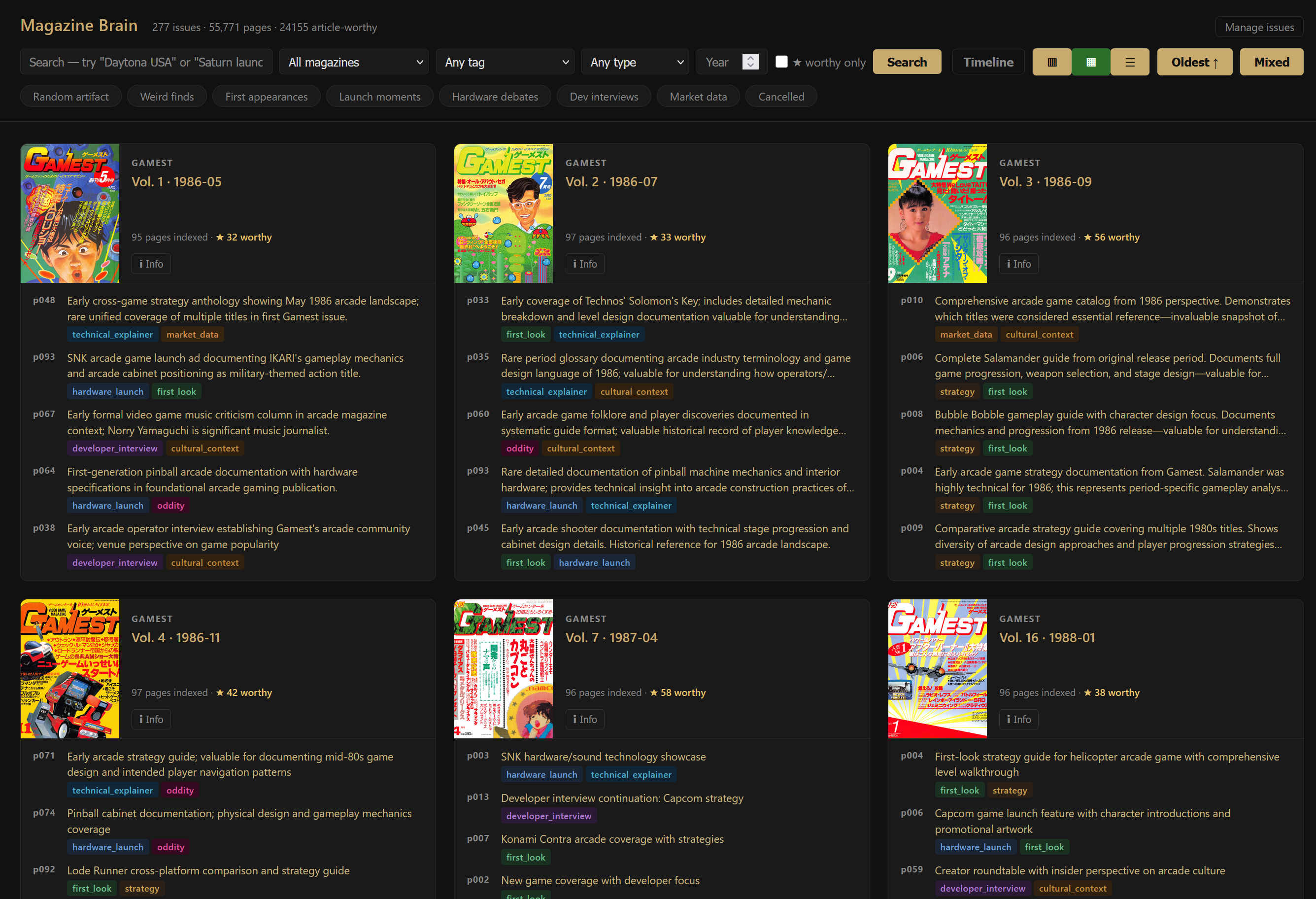
The Archive
AI-powered exploration of historical Japanese magazines.
Many historical Japanese magazines exist as scans but remain invisible to search engines. The Archive turns image-only magazine scans into searchable, cited, cross-magazine knowledge.
Show me
What you can ask the archive
The useful surface is not the pipeline. It is the ability to ask historical questions across magazines and land back on cited pages.
Show every issue that mentioned Virtua Fighter before launch.
Find Sega Saturn advertisements from 1995 and group them by publisher.
Trace how PC-98 adventure and eroge coverage changes across the 1990s.
Find every article, ad, and interview mentioning Yu Suzuki.
Current interface
The prototype already has searchable issue grids, result views, page-level evidence, and generated deep dives tied back to scanned source pages.
1,400+
Magazines registered
current internal corpus
220k+
Pages indexed
current prototype metrics
58k+
Ads catalogued
across scanned issues
93%
Retrieval hit@10
golden-set evaluation
Example outputs
Search result example
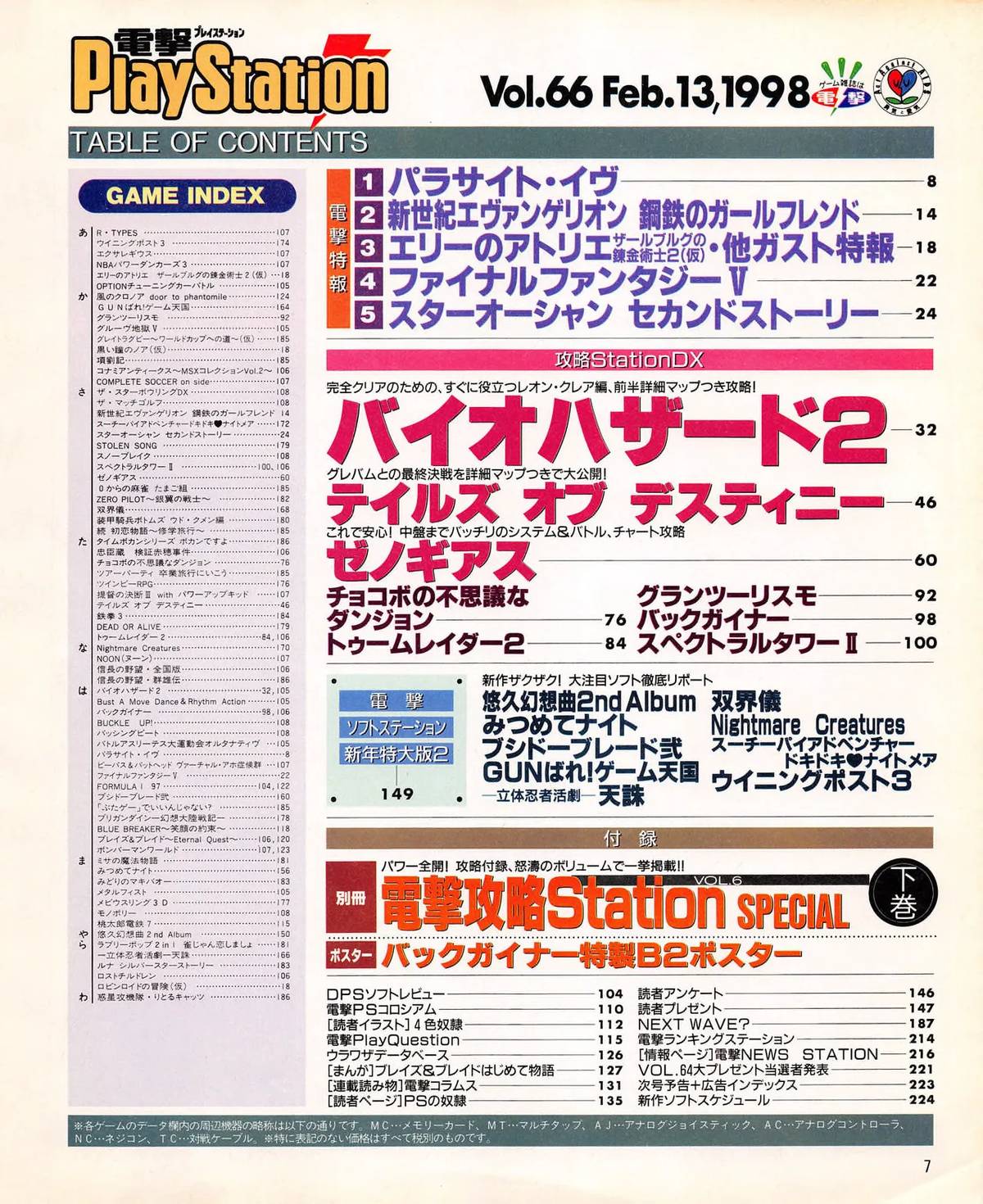
Parasite Eve, February 1998
Dengeki PlayStation Vol. 66 pages 9-17 and Dengeki Oh! Vol. 72 pages 29-31 surface as connected primary sources: pre-release CG coverage, developer interview, credited staff, and a release-date discrepancy.
Deep dive example
A Digital Domain veteran inside Square USA
The generated article connects Steve Gray, Sakaguchi Hironobu, Tokita Takashi, Square USA, CG production, and the language barrier described in the original interview.
Entity page example
Game: Parasite Eve
A game record can collect issue mentions, ads, people, companies, source pages, historical tags, and cited magazine evidence rather than a single detached summary.
Where this is going
Search today, cited answers tomorrow
Each phase reuses the data created by the one below it. Every correction, canonical entity, and newly indexed publication raises the ceiling for search and the future answer layer.
Archive
done
Scans exist, are registered, and can be browsed as source material.
Knowledge base
here now
Pages become indexed, corrected, and searchable metadata with source context.
Research tool
next
A question returns cited answers grounded in issue, page, image, and entity evidence.
Public interface
future
A hosted research surface for Japanese game, anime, and otaku magazine history.
Corpus sample
Publishers in the archive
Gamest
Arcade coverage, strategy, operators, launch context
1980s-1990s

Technical differentiator
Extraction != Truth. Extraction -> Review -> Truth.
Most AI extraction systems overwrite data. The Archive treats each extraction as a proposal. New information passes through correction gates and review before it becomes canonical metadata.
Why it matters
These magazines document game history, fan culture, advertisements, release coverage, creator credits, and forgotten commercial context that normal web search cannot reach.
The project treats scanned magazines as primary sources. The goal is not to summarize from memory; it is to make issue, page, title, person, company, ad, and historical-tag evidence searchable across magazines.
Page-level evidence
Each page keeps the original scan visible alongside extracted metadata and generated context. Strategy guides, hardware ads, interviews, reviews, contents pages, and multi-page spreads can be inspected as evidence rather than detached snippets.
Search results surface the issue, page number, description, tags, and entities that made the page relevant. The interface is intentionally plain: the source image stays close to the structured claim.


A real deep dive
One generated article connects Dengeki PlayStation Vol. 66 and Dengeki Oh! Vol. 72 around Parasite Eve in February 1998. The system pulls together a nine-page pre-release scoop, a same-month developer interview, CG pipeline context, credited staff, and a release date discrepancy: one magazine page lists March 19, while the game shipped March 29.
That is the kind of research this archive is meant to enable: not a generic summary of a famous game, but a cited path through primary magazine pages that reveals what contemporary coverage actually said.


Google Cloud fit
The next bottleneck is not interface polish; it is reliable bulk processing. Cloud credits would support larger OCR and vision runs, embedding refreshes, evaluation sweeps, hosted review queues, and a small public research preview without pushing everything through local machines or fragile free-tier limits.
This is a practical cloud workload: batch image processing, structured extraction, queue-backed pipelines, retrieval indexes, evaluation jobs, and eventually a cited answer layer over historical primary sources.
Architecture summary
The full engineering appendix keeps the daemon, lock, queue, and model-routing details out of the main pitch.
Highlights
- ▶Database-as-queue architecture: registration, not processing, enqueues work; every stage is resumable and idempotent
- ▶Correction gate: model output is treated as a proposal, with safe additive deltas separated from review-required replacements
- ▶Multi-model extraction: broad vision passes, stronger models for gap-fill and deep dives, and model-independent schemas for reruns
- ▶Hybrid retrieval: lexical, dense, and facet-aware search evaluated against a golden set, currently 93% hit@10
- ▶Credible research corpus: 1,400+ registered magazines, 220k+ indexed pages, and 58k+ advertisements catalogued in the current internal prototype
Under the hood
Useful for
Current status
This is an active personal research and build project. The system is working internally; public access is not yet open.